
시스템 보안(1) - 프롤로그/에필로그, 호출 규약, BOF, 보호 기법
시스템 보안에 대해 공부해봅시다✨
해당 내용은 x86-64 (Intel, 64bit CPU) 기반입니다.
0. 선수 지식
본격적인 내용에 들어가기에 앞서, 64bit와 32bit CPU의 차이와 스택 구조에 대해서 정리하도록 하겠습니다.
64bit CPU와 32bit CPU의 차이는 아래와 같습니다.
| 구분 | 32bit | 64bit |
|---|---|---|
| int | 4B | 4B |
| float | 4B | 4B |
| double | 8B | 8B |
| short | 2B | 2B |
| pointer | 4B | 8B |
| register | 4B | 8B |
pointer는 메모리 주소값을 저장하기 때문에 CPU의 아키텍쳐에 따라 달라지며, 레지스터의 경우에도 CPU가 한 번에 처리할 수 있는 데이터 크기와 밀접한 관계를 가지기 때문에 64bit CPU에서는 범용 레지스터의 크기가 2배로 확장됩니다.
메모리 구조는 아래와 같습니다.
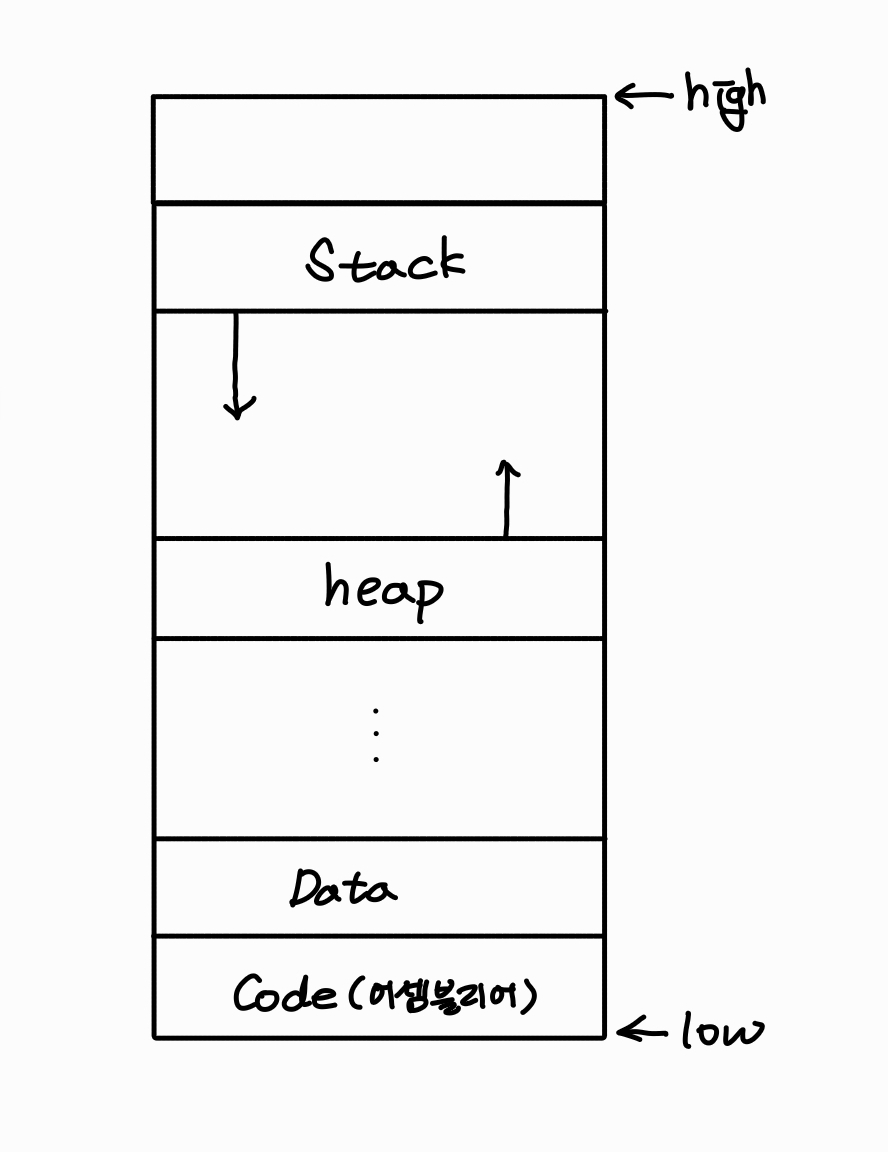
이 포스트에서 중점적으로 공부할 부분은 스택입니다.
스택은 다른 구조와 달리 위에서 아래로 자랍니다.
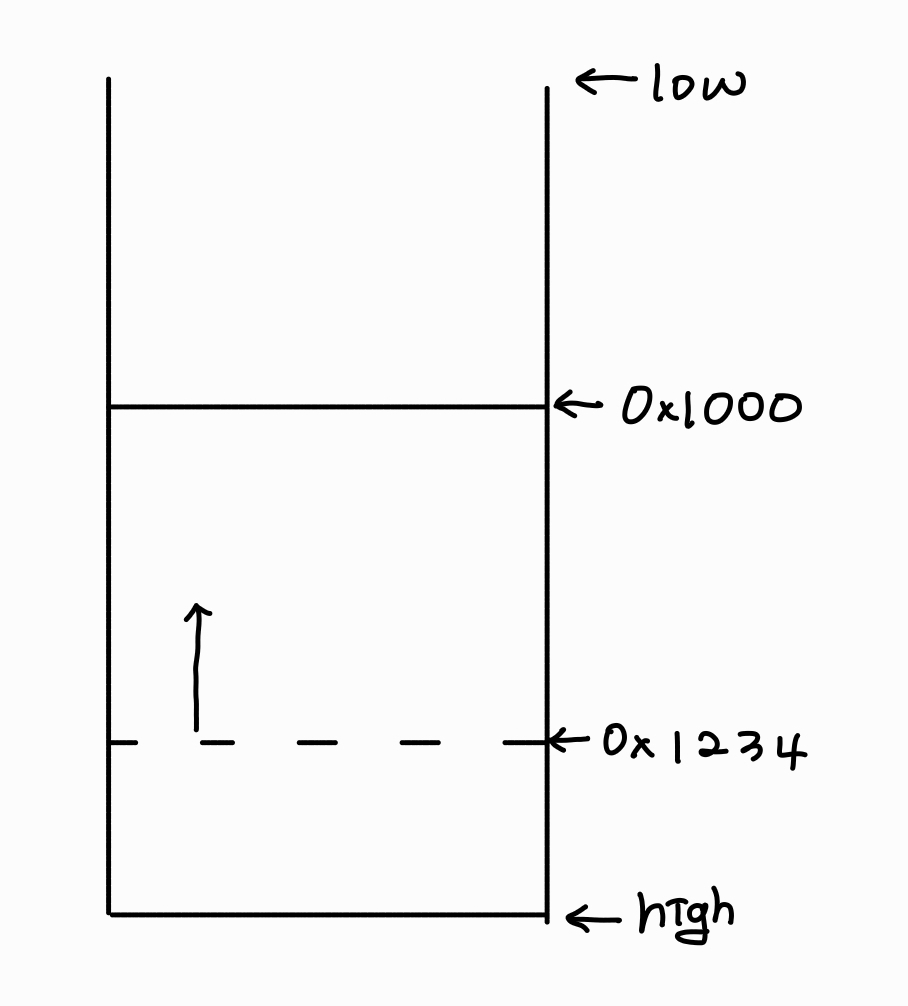
앞으로는 가시성을 위해 위의 그림과 같이 high address를 아래로, low address를 위로 향하게 하여 스택 구조를 표현할 예정입니다.
스택의 top의 주소를 알고 있어야 push와 pop을 할 수 있기 때문에 이 top의 주소를 저장하는 특수한 레지스터인 rsp가 존재합니다.
그리고 bottom 주소를 저장하는 rbp라는 레지스터도 있습니다.
이 rbp는 현재 함수의 시작 지점이 되어줍니다.
이제 스택이 사용할 수 있는 공간을 키우려면 주소를 어떻게 조작해주어야 할까요?
스택은 위에서 아래로 자라기 때문에 주소값이 작아져야 합니다.
위의 그림을 상세히 보시면 원래 top 주소, 즉 rsp가 가리키는 주소값이 0x1234였다가 0x1000으로 작아지며 가용 범위가 넓어진 것을 확인할 수 있습니다.
정말 헷갈리지만, 꼭 기억해야 합니다.
그렇다면, rsp가 0x1000인 경우에 특정 데이터가 저장된다면 1번과 2번 중 어디에 저장될까요?
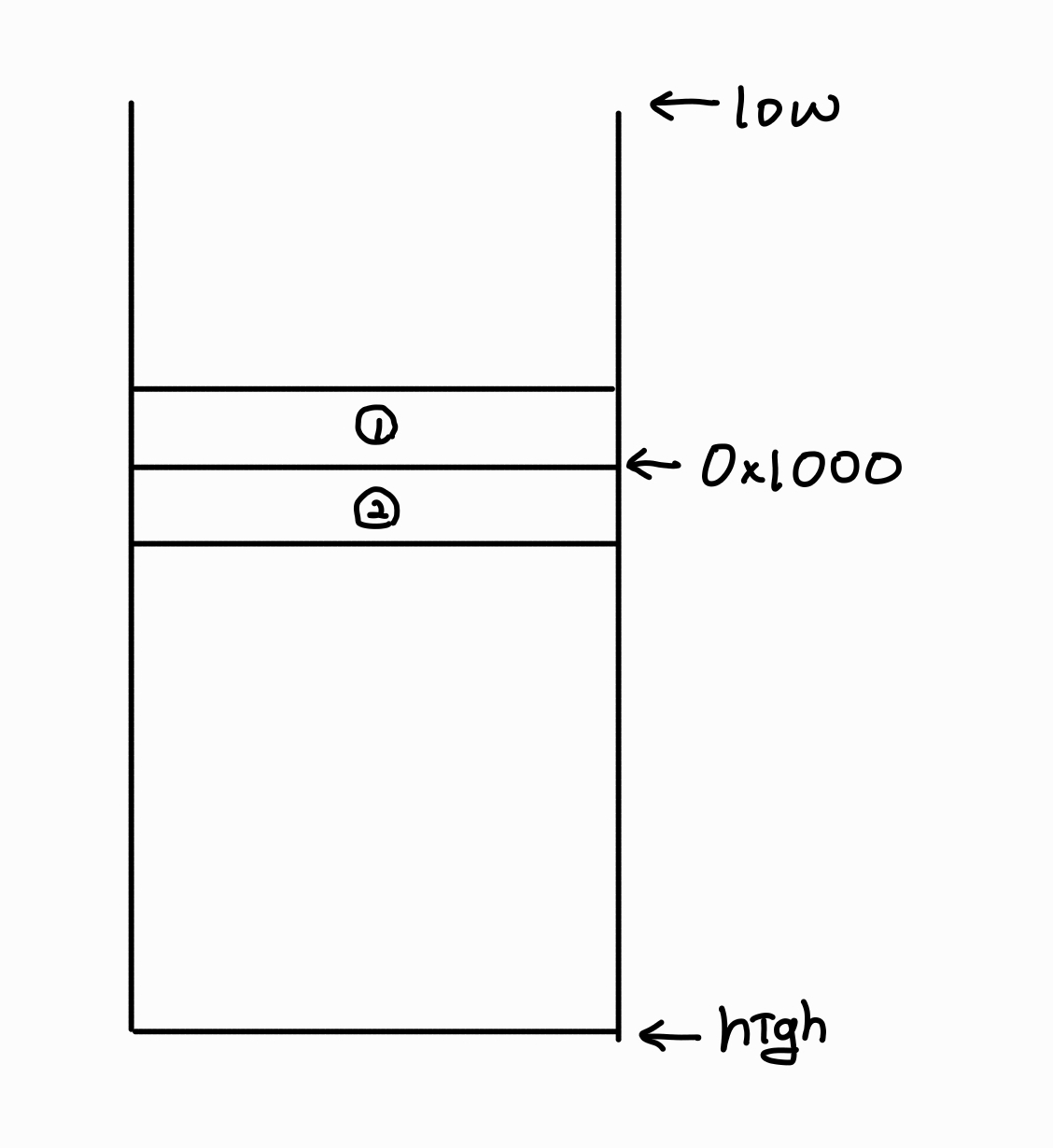
2번 공간에 저장됩니다.
따라서, 늘어난 공간 안에 데이터가 저장된다는 느낌으로 생각하시면 보다 쉽게 이해할 수 있을 거예요.
1. 프롤로그와 에필로그
스택은 마치 대나무와 같은 형태를 띄고 있습니다.
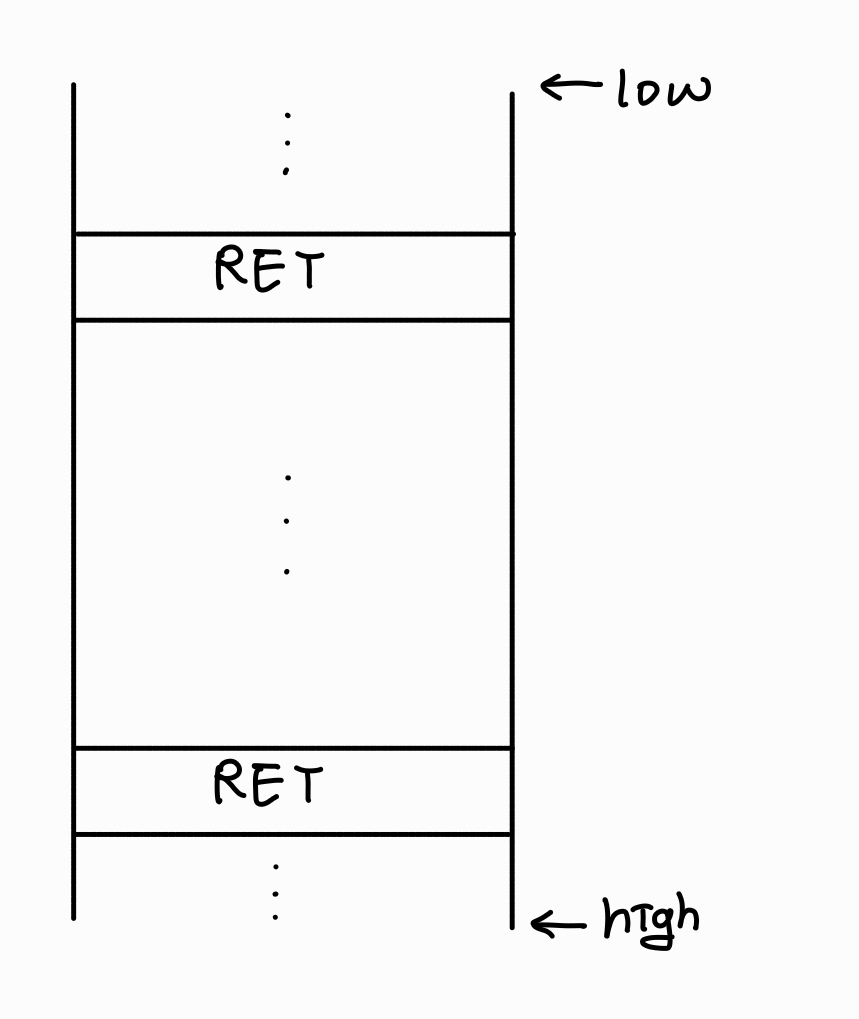
이 한 마디가 하나의 함수라고 생각하면 됩니다.
그리고 이 한 마디를 스택 프레임이라고 합니다!
스택은 함수의 놀이터라고 불릴 정도로 함수를 관리하는데 정말 적합한 구조예요.
아래의 내용을 읽다보면 스택이라는 구조가 왜 아름다운지, 이걸 처음 구상한 엘런 튜링이 얼마나 대단한 사람인지 느낄 수 있습니다.
자, 다시 돌아와서
하나의 어셈블리어 코드에서 함수를 잘 구분할 수 있게 된다면, 그 스택 구조를 쉽게 파악하는데 도움이 될 수 있습니다.
이 때 사용할 수 있는 것이 바로, 프롤로그와 에필로그입니다.
1-1. 프롤로그
프롤로그라는 이름에서 알 수 있듯이, 함수가 시작되면 가장 먼저 실행되는 준비 과정이 있습니다.
push rbp
mov rbp, rsp
이 두 줄이 바로 프롤로그입니다.
push로 RET 위에 rbp가 원래 위치하던 주소 값을 저장합니다.
이후, mov를 통해 스택의 top을 가리키던 rsp의 주소값을 rbp에 복사하게 되면서 두 레지스터가 같은 주소값을 가리키게 됩니다.
즉, 스택의 top을 rsp와 rbp 둘 다 가리키게 됩니다.
해당 과정을 그림으로 그리면 아래와 같습니다.
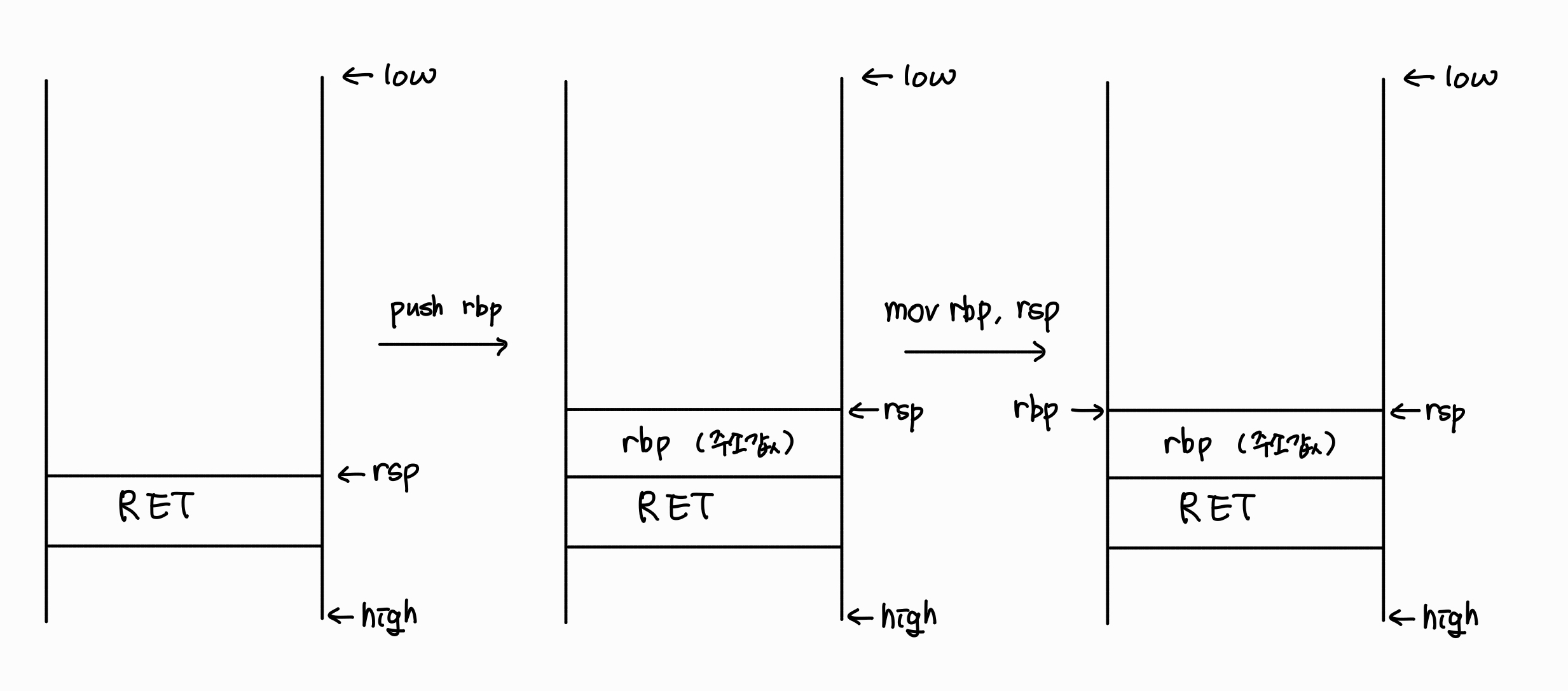
1-2. 에필로그
에필로그는 프롤로그와 반대로 함수의 작동이 끝난 뒤, 원래의 상태로 돌아가는 마무리 과정입니다.
leave
ret
에필로그는 간단하게 leave와 ret으로 표기됩니다.
leave와 ret이 동작하는 방식을 조금 더 자세하게 보겠습니다.
leave
mov rsp, rbp
pop rbp
mov가 스택의 top을 가리키고 있던 rsp에 rbp의 주소값을 복사하며 rsp가 rbp와 같은 주소를 가리키게 됩니다.
이후, pop을 통해 rbp에 기존에 저장되어 있던 rbp의 주소값이 저장되며 rbp는 원래의 위치로 돌아가게 되고, rsp는 pop으로 인해 변경된 스택의 top을 가리키게 됩니다.
이 때, 아주 신기하고 놀라운 사실이 있는데요, leave가 동작하더라도 스택은 0으로 초기화되지 않으며 pop이 동작될 때도 데이터가 사라지거나 0으로 초기화 되지 않습니다!
즉, leave나 pop 명령은 단순히 레지스터를 이동시키는 것일 뿐, 실제 스택의 메모리 공간에 저장된 값은 지워지거나 초기화되지 않습니다.
사실 하나하나 초기화 하는 과정이 컴퓨터의 입장에서는 자원 낭비입니다. 왜냐하면 어차피 나중에 새로운 데이터를 입력해야 할 때 데이터를 덮어쓰면 상관이 없을 테니까요.
따라서, 스택은 전적으로 rsp에 의존하며, rsp 안의 내용만을 데이터로 받아들입니다.
제가 사실 이 내용이 매우 흥미로웠던 것은 기존에 데이터 구조 등의 수업에서 스택을 배울 때 데이터가 push/pop 되는 것을 학생들이 이해하기 쉽도록 아예 스택에서 데이터가 삽입되고 삭제되는 형식으로 표기 되었기 때문에 사실 컴퓨터의 측면에서는 데이터가 한 번도 초기화 되거나 삭제된 적이 없다는 사실이 너무나 신기했습니다.
그런데 곰곰이 생각해보면, 컴퓨터가 이렇게 작동되기 때문에 포렌식이나 리버싱 등이 가능한 것이더라구요.
아무튼, 그림으로 표현하면 아래와 같습니다.
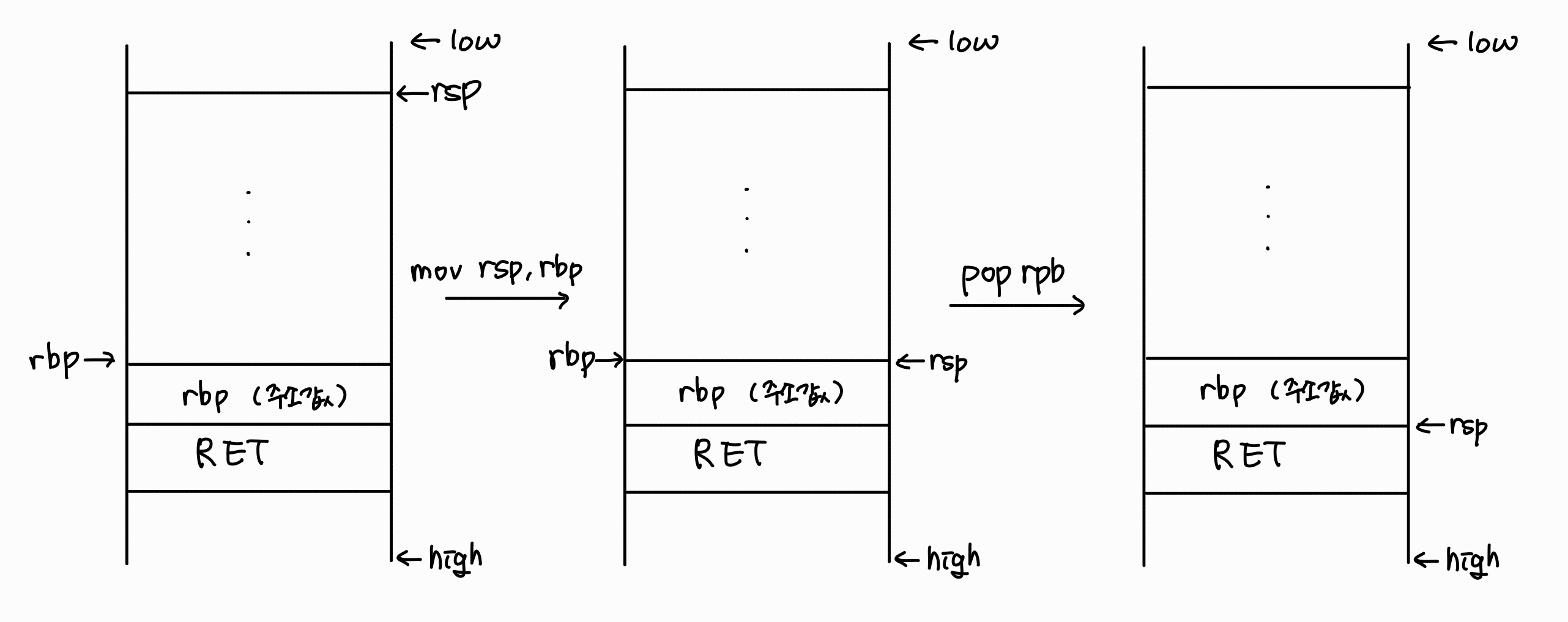
자 이제 ret입니다.
ret
pop rip
jmp *rip
여기서 rip는 다음으로 실행시킬 명령어의 주소를 가리킵니다.
따라서, pop을 통해 가장 최상단에 있던 RET에 저장되어 있던 다음으로 실행할 함수의 주소, 즉 복귀 주소가 rip에 저장되며 rsp 또한 변경된 top을 가리키게 됩니다.
이후, jmp를 통해 해당 주소로 이동하며 프로그램의 흐름을 복귀 시킵니다.
최종적으로, 스택에서 해당 함수가 제거된 효과를 낼 수 있습니다!
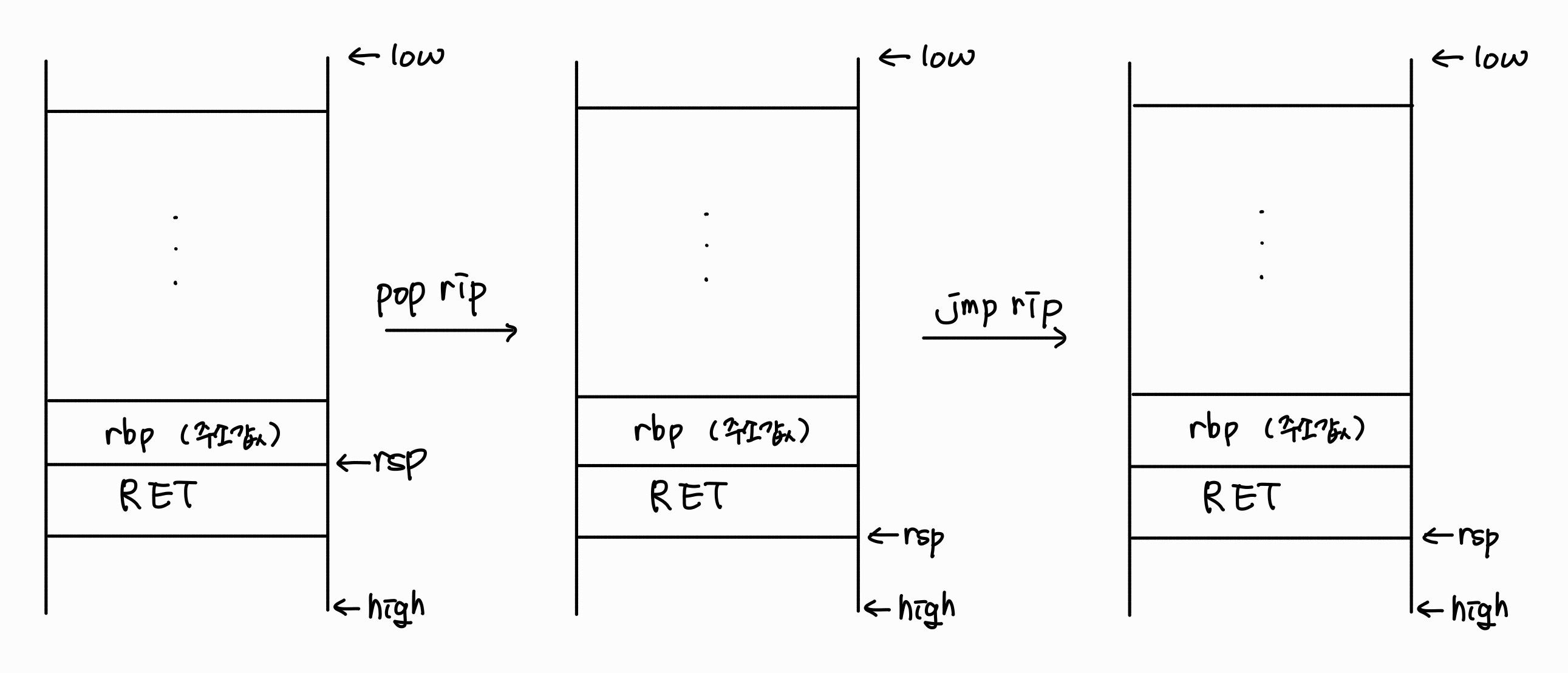
2. Calling Convention (호출 규약)
Calling Convention은 함수 호출 시에 어떻게 인자를 전달할 것인지를 정하는 규약입니다.
Calling Convention은 아래와 크게 아래와 같이 나누어집니다.
- 변수 보존
- 파라미터 전달
이 포스트에서는 파라미터 전달에 대해서 정리해보겠습니다.
파라미터 전달은 32bit CPU를 사용할 때와 64bit CPU를 사용할 때에 다르게 규약이 적용됩니다.
2-1. 32bit CPU
32bit의 경우, 그냥 스택에 push하고 알아서 사용하도록 둡니다.
별다른 규칙 없이 그냥 스택에 push합니다.
그러나, 레지스터를 사용하지 않고 스택을 사용하기 때문에 다소 비효율적입니다.
2-2. 64bit CPU
64bit의 경우 딱 6개의 레지스터만 순서대로 외우면 됩니다.
rdi, rsi, rdx, rcx, r8, r9
이 순서대로 6개의 레지스터에 차례대로 저장하며, 이 순서는 무조건 지켜져야 합니다.
따라서, 함수가 실행될 때 원하는 매개변수가 해당 위치에 있을 것이라고 믿고 찾아 사용합니다.
만약, 6개가 넘는 파라미터를 사용하는 경우에는 6개까지는 레지스터에 저장하고 7번째부터 스택에 저장합니다.
그러나, 스택은 메모리라 레지스터에 비해 비효율적 이므로 자원을 효율적으로 사용하기 위해서는 파라미터를 최대 6개까지만 사용하는 것이 좋습니다.
이 규약을 이용한 것이 ROP입니다.
ROP는 간단하게 설명하면 파라미터가 레지스터에 순서대로 저장되어야 하는데, 이 순서를 조작하여 의도하지 않은 함수를 호출하거나 시스템을 제어하는 공격입니다.
ROP는 다른 포스트에서 자세히 다뤄볼 예정입니다!
3. BOF - Buffer overflow
BOF는 메모리에 접근 할 때, 입력 데이터를 처리할 때 버퍼의 크기를 초과하는지 검사하지 않는 취약점에서 시작된 공격 기법입니다.
따라서, 의도한 크기보다 더 큰 범위에 데이터를 덮어쓸 수 있습니다.
이를 이용해서 원래라면 접근할 수 없는 공간에 공격자가 임의의 데이터를 덮어쓰는 공격이 바로 BOF입니다.
그러면, 위의 내용을 바탕으로 어셈블리어 코드를 한 번 분석해보며 BOF가 어떻게 작용하는지에 대해서 알아보겠습니다.
3-1. 분석
#include <stdio.h>
#include <stdlib.h>
main() {
char buf[10];
gets(buf);
printf("%s", buf);
return 0;
}
우선, 위와 같은 test.c 파일을 만들어 주었습니다.
그리고 이걸 컴파일 해줍니다.
gcc test.c -o test test.c라는 파일을 test라는 이름의 실행 파일로 컴파일하라는 명령어입니다.
원래 BOF 실습을 위해서는 BOF를 막기 위한 여러 보호 기법들을 꺼주는 커멘드를 입력해서 컴파일 해야합니다.
하지만, 저는 이 포스트에서 BOF 공격의 이론과 보호 기법들에 대해 정리할 예정이기 때문에 그냥 컴파일 했습니다.
보호 기법을 설명하면서 각각의 보호 기법을 끄는 커멘드에 대해 작성해두도록 하겠습니다.
컴파일 후에 gdb를 이용해 어셈블리어 코드를 확인해보겠습니다.
sudo apt install gdb 설치해주고,
gdb ./test 실행해줍니다.
gdb가 실행되면 저는 intel 문법을 사용하므로 set disassembly-flavor intel로 인텔 문법으로 설정해줍니다.
그리고 disassemble main을 입력해 main 함수를 디스어셈블 해줍니다.
0x0000000000001189 <+0>: endbr64
0x000000000000118d <+4>: push rbp
0x000000000000118e <+5>: mov rbp,rsp
0x0000000000001191 <+8>: sub rsp,0x20
0x0000000000001195 <+12>: mov rax,QWORD PTR fs:0x28
0x000000000000119e <+21>: mov QWORD PTR [rbp-0x8],rax
0x00000000000011a2 <+25>: xor eax,eax
0x00000000000011a4 <+27>: lea rax,[rbp-0x12]
0x00000000000011a8 <+31>: mov rdi,rax
0x00000000000011ab <+34>: mov eax,0x0
0x00000000000011b0 <+39>: call 0x1090 <gets@plt>
0x00000000000011b5 <+44>: lea rax,[rbp-0x12]
0x00000000000011b9 <+48>: mov rsi,rax
0x00000000000011bc <+51>: lea rax,[rip+0xe41] # 0x2004
0x00000000000011c3 <+58>: mov rdi,rax
0x00000000000011c6 <+61>: mov eax,0x0
0x00000000000011cb <+66>: call 0x1080 <printf@plt>
0x00000000000011d0 <+71>: mov eax,0x0
0x00000000000011d5 <+76>: mov rdx,QWORD PTR [rbp-0x8]
0x00000000000011d9 <+80>: sub rdx,QWORD PTR fs:0x28
0x00000000000011e2 <+89>: je 0x11e9 <main+96>
0x00000000000011e4 <+91>: call 0x1070 <__stack_chk_fail@plt>
0x00000000000011e9 <+96>: leave
0x00000000000011ea <+97>: ret
그러면 이렇게 어셈블리 코드를 확인할 수 있습니다.
분석해보겠습니다.
0x0000000000001189 <+0>: endbr64
0x000000000000118d <+4>: push rbp
0x000000000000118e <+5>: mov rbp,rsp
0x0000000000001191 <+8>: sub rsp,0x20
이 코드의 2, 3번 줄이 바로 프롤로그입니다.
프롤로그를 통해 rsp와 rbp가 위치하게 되면, rsp의 주소가 0x20만큼 줄어들며 공간을 확보합니다.
sub rsp, 0x20 명령으로 스택 공간이 32바이트 확보되었지만, 이는 단순히 지역변수인 buf[10] 때문만은 아닙니다.
stack alignment나 보호 기법 등으로 사용되는 공간 등을 고려하여 여유 공간을 함께 할당할 수 있기 때문에, 실제로 어느 정도의 공간이 사용되었는지는 디버거를 통해 확인하는 것이 가장 정확합니다.
위의 코드를 그림으로 그려보면 아래와 같습니다.
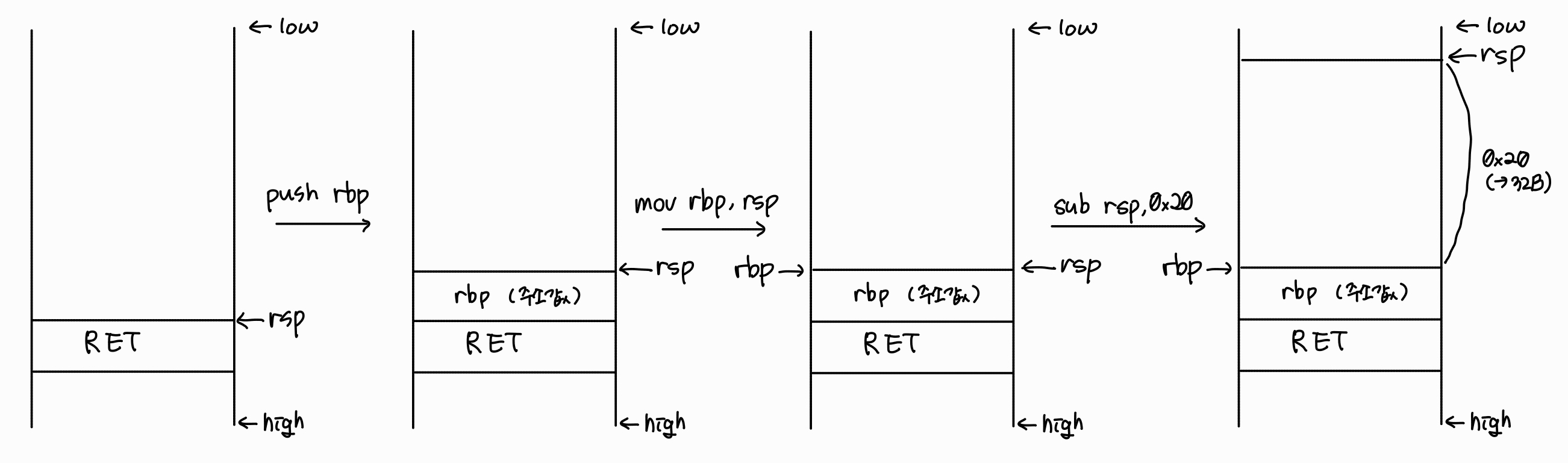
0x0000000000001195 <+12>: mov rax,QWORD PTR fs:0x28
0x000000000000119e <+21>: mov QWORD PTR [rbp-0x8],rax
이 코드는 스택 보호 기법인 canary를 위한 값 설정이 진행되는 코드입니다.
랜덤한 값을 QWORD, 즉 8B만큼의 공간 안에 저장해두고, 함수 종료 시점에 이를 비교하여 스택 변조 여부를 확인합니다.
0x00000000000011a2 <+25>: xor eax,eax
0x00000000000011a4 <+27>: lea rax,[rbp-0x12]
0x00000000000011a8 <+31>: mov rdi,rax
0x00000000000011ab <+34>: mov eax,0x0
0x00000000000011b0 <+39>: call 0x1090 <gets@plt>
이 코드는 gets를 호출하는 코드입니다.
1번 줄로 eax를 0으로 초기화 해주고, 2번 줄로 lea 연산을 통해 rax에 rbp-0x12라는 주소값을 저장해줍니다.
그리고, rbp-0x12라는 주소가 buf의 시작 주소임을 알 수 있습니다.
3번 줄을 통해 rdi에 rax에 저장해두었던 주소값을 저장해줍니다.
드디어 첫 번째 파라미터가 등장했다는 것을 알 수 있습니다. rdi가 사용되었으니까요!
그리고 4번 줄을 통해 현재 호출에서는 가변 인자가 없음을 명시합니다.
그리고 5번 줄을 통해 gets 함수를 호출합니다!
자 그러면 실제 소스코드랑 비교를 해봅시다.
이 부분에 맞는 소스코드는
char buf[10];
gets(buf);
이렇게 두 줄입니다.
확인해보면, gets 함수에는 buf라는 하나의 파라미터만 사용되었고, 가변 인자가 없다는 것을 확인할 수 있습니다.
여기까지 그림으로 나타내면 아래와 같이 표현할 수 있습니다.
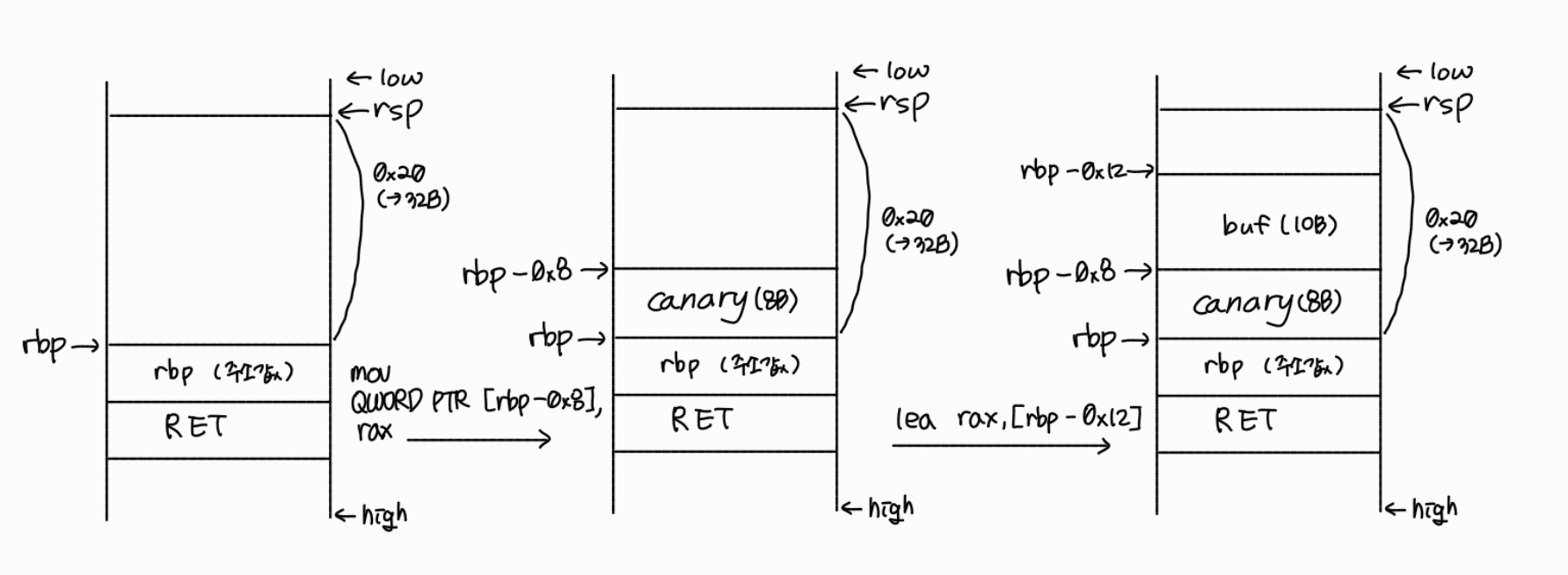
0x00000000000011b5 <+44>: lea rax,[rbp-0x12]
0x00000000000011b9 <+48>: mov rsi,rax
0x00000000000011bc <+51>: lea rax,[rip+0xe41] # 0x2004
0x00000000000011c3 <+58>: mov rdi,rax
0x00000000000011c6 <+61>: mov eax,0x0
0x00000000000011cb <+66>: call 0x1080 <printf@plt>
0x00000000000011d0 <+71>: mov eax,0x0
이 코드는 printf를 호출하는 코드입니다.
구성은 대체로 gets 함수 호출 코드와 유사하지만, 3번 줄이 추가되어 있습니다.
이 3번 줄은 rip, 즉 현재 명령어의 주소에 오프셋을 더한 주소 값을 rax에 저장하고 있습니다.
이후 이 값이 rdi에 저장되며 printf의 첫번째 파라미터로 사용되는 것을 볼 수 있습니다.
즉, 3번 줄은 %s와 같은 문자열 리터럴이나 전역 변수 등을 처리하는 명령어입니다.
왜 이렇게 복잡하게 데이터를 불러올까요?
이는 PIE(Position Independent Executable) 보호 기법 때문입니다.
PIE는 프로그램이 메모리에서 매번 다른 주소에 매핑되도록 하여, 정적 주소를 기반으로 한 공격을 어렵게 만드는 보안 기법입니다.
0x00000000000011d5 <+76>: mov rdx,QWORD PTR [rbp-0x8]
0x00000000000011d9 <+80>: sub rdx,QWORD PTR fs:0x28
0x00000000000011e2 <+89>: je 0x11e9 <main+96>
0x00000000000011e4 <+91>: call 0x1070 <__stack_chk_fail@plt>
이 코드는 스택이 잘 보호되었는지 검사하는 canary check 코드입니다.
1번 줄로 rbp-0x8부터 저장되어 있는 데이터를 rdx에 저장하여 2번 줄에서 처음에 불러왔던 카나리 값과 sub 연산을 실시해줍니다.
만약, sub 연산 결과가 0이라면 3번 줄을 통해 main+96에 해당 하는 라인으로 이동하고, sub 연산 결과가 1이 아니라면 카나리 값이 변조된 것을 의미하기 때문에 __stack_chk_fail() 함수를 호출하고 프로그램을 강제로 종료 시킵니다.
자 이제 마지막으로 에필로그를 분석해봅시다.
0x00000000000011e9 <+96>: leave
0x00000000000011ea <+97>: ret
이 에필로그를 통해 return address로 점프하고 마무리됩니다.
그림으로 정리하면, 아래와 같습니다.
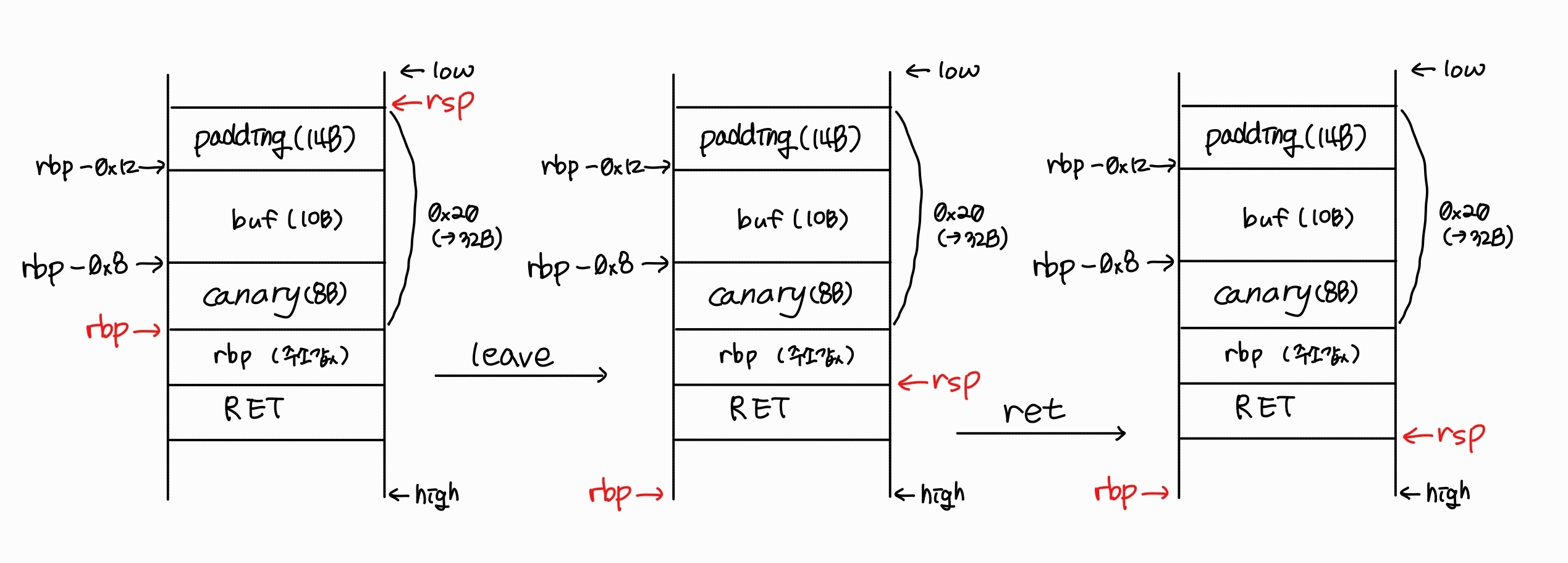
rsp와 rbp를 빨간색으로 표시해두었으니, 위의 1. 프롤로그와 에필로그에서 자세히 설명해두었던 과정과 비교해가면서 다시 한 번 보면 좋을 것 같습니다.
아 그리고, 위에 padding은 stack alignment나 보호 기법 등으로 사용되는 공간 또한 컴파일러 내부에서 자체적으로 함께 할당된 공간입니다.
3-2. BOF 공격
자 그러면 BOF 공격을 한 번 시도해봅시다!
보호 기법이 아무 것도 적용되어 있지 않다고 가정하고, 스택을 그려보았습니다.
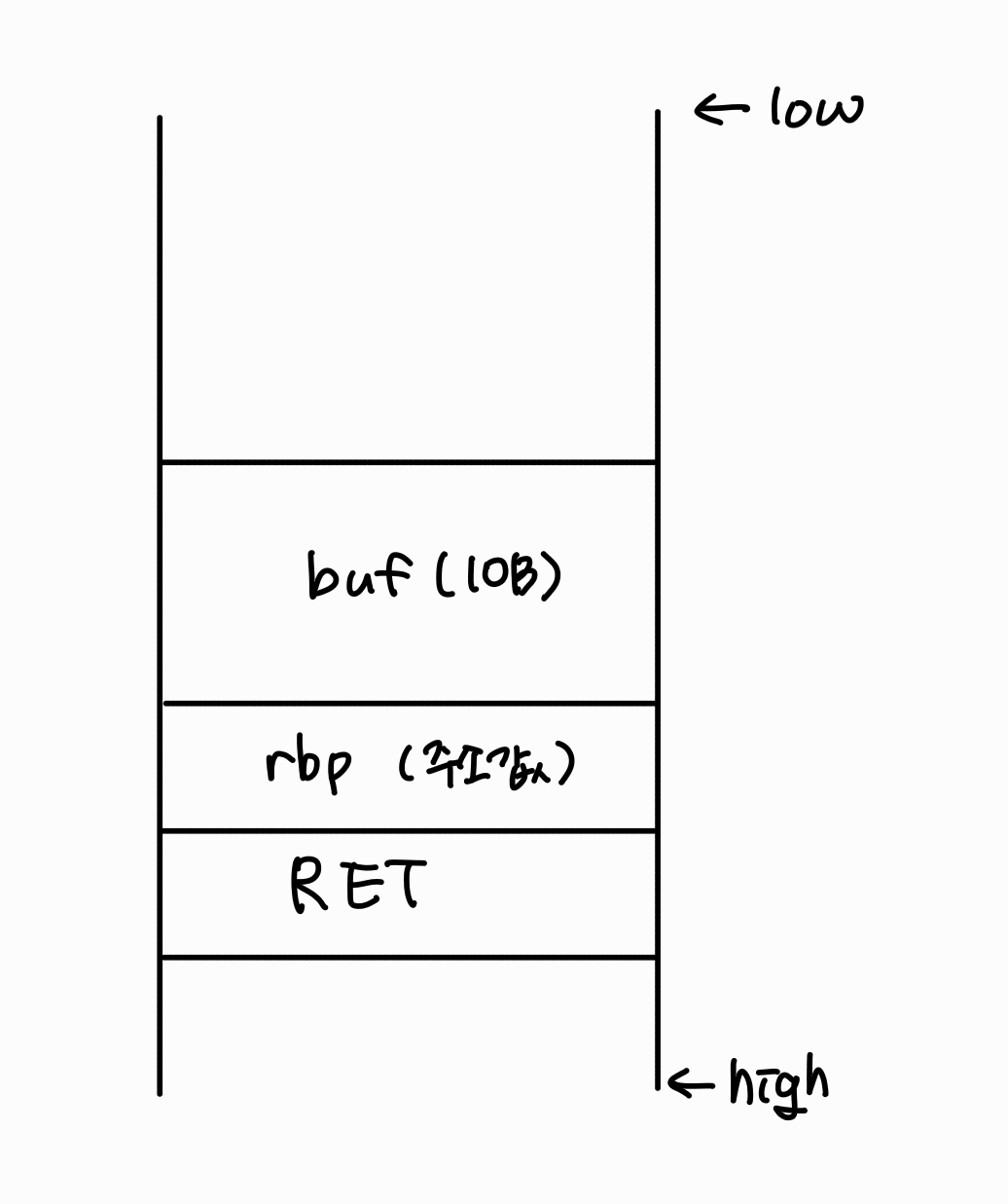
이렇게 스택이 구성되어 있다면, 우리의 목표는 buf에 할당된 공간 보다 더 넓은 공간을 데이터로 덮어 씌워 RET에 우리가 원하는 함수의 시작주소로 덮어 씌워 주는 것입니다.
이 예시에서는 buf가 10B, rbp가 8B 이므로 18B의 값 뒤에 원하는 주소를 적어주면 됩니다.
주소를 기입할 때에는 x86 CPU는 little endian 방식을 차용하기 때문에 역순으로 \x87\x65\x43\x21과 같이 작성해야 합니다!!
그러면 공격 완료!
4. 보호 기법
4-1. Canary
- BOF 공격을 방어를 위해 스택을 변조로 부터 보호하는 기법입니다. 위의 어셈블리어 분석 단계에서 자세히 설명한 것처럼 랜덤값을 중간에 저장해두고, 함수 종료 직전에 변조되었는지 확인합니다.
- 그러나, read 등으로 카나리 값이 유출 가능하며 이러한 공격을 Canary Leak이라고 합니다.
- 컴파일 시에
gcc -fno-stack-protector test.c -o test이러한 방식으로-fno-stack-protector옵션을 넣어주면 카나리를 끌 수 있습니다. - 카나리를 끄게 되면 위의 코드를 디스어셈블한 결과가 아래와 같이 나옵니다.
# 카나리 값 할당 코드나 비교 코드가 존재하지 않음.
0x0000000000001169 <+0>: endbr64
0x000000000000116d <+4>: push rbp
0x000000000000116e <+5>: mov rbp,rsp
0x0000000000001171 <+8>: sub rsp,0x10 # 스택 공간이 16B만 할당됨.
0x0000000000001175 <+12>: lea rax,[rbp-0xa]
0x0000000000001179 <+16>: mov rdi,rax
0x000000000000117c <+19>: mov eax,0x0
0x0000000000001181 <+24>: call 0x1070 <gets@plt>
0x0000000000001186 <+29>: lea rax,[rbp-0xa]
0x000000000000118a <+33>: mov rsi,rax
0x000000000000118d <+36>: lea rax,[rip+0xe70] # 0x2004
0x0000000000001194 <+43>: mov rdi,rax
0x0000000000001197 <+46>: mov eax,0x0
0x000000000000119c <+51>: call 0x1060 <printf@plt>
0x00000000000011a1 <+56>: mov eax,0x0
0x00000000000011a6 <+61>: leave
0x00000000000011a7 <+62>: ret
4-2. NX
- shell code injection을 방지하기 위한 보호 기법입니다. 스택 자체에 권한을 rw_로 하거나 w^x로 부여합니다. (보통 w^x)
- shell code injection: 스택에 쉘 코드를 넣어두고, 해당 코드의 시작 주소에 rip를 위치 시켜 실행시키는 공격
- w^x로 권한을 부여하면 스택에 쓰고 실행을 시킬 수 없기 때문에 쉘 코드를 넣고 실행 시키는 일련의 행위가 불가능 해집니다.
- 이로 인해 shell code injection 공은 거의 불가능해졌습니다.
4-3.PIE
- 정적 주소 공격을 방지하기 위한 보호 기법입니다. 실행 시킬 때마다 매번 다른 주소에 매핑되도록 하는 기법입니다.
- 그러나, 하나의 명령어라도 실제 주소를 알게 된다면 파훼가 가능합니다.
- 컴파일 시에 카나리 옵션과 같은 위치에
-no-pie -fno-pie를 기입하면 PIE를 끌 수 있습니다.# 실행 전 0x0000000000001189 <+0>: endbr64 0x000000000000118d <+4>: push rbp 0x000000000000118e <+5>: mov rbp,rsp 0x0000000000001191 <+8>: sub rsp,0x20 0x0000000000001195 <+12>: mov rax,QWORD PTR fs:0x28 0x000000000000119e <+21>: mov QWORD PTR [rbp-0x8],rax 0x00000000000011a2 <+25>: xor eax,eax 0x00000000000011a4 <+27>: lea rax,[rbp-0x12] 0x00000000000011a8 <+31>: mov rdi,rax 0x00000000000011ab <+34>: mov eax,0x0 0x00000000000011b0 <+39>: call 0x1090 <gets@plt> 0x00000000000011b5 <+44>: lea rax,[rbp-0x12] 0x00000000000011b9 <+48>: mov rsi,rax 0x00000000000011bc <+51>: lea rax,[rip+0xe41] # 0x2004 0x00000000000011c3 <+58>: mov rdi,rax 0x00000000000011c6 <+61>: mov eax,0x0 0x00000000000011cb <+66>: call 0x1080 <printf@plt> 0x00000000000011d0 <+71>: mov eax,0x0 0x00000000000011d5 <+76>: mov rdx,QWORD PTR [rbp-0x8] 0x00000000000011d9 <+80>: sub rdx,QWORD PTR fs:0x28 0x00000000000011e2 <+89>: je 0x11e9 <main+96> 0x00000000000011e4 <+91>: call 0x1070 <__stack_chk_fail@plt> 0x00000000000011e9 <+96>: leave 0x00000000000011ea <+97>: ret# gdb에서 run main으로 실행 후 # 메모리 주소가 달라진 것을 확인 할 수 있습니다. 0x0000555555555189 <+0>: endbr64 0x000055555555518d <+4>: push rbp 0x000055555555518e <+5>: mov rbp,rsp 0x0000555555555191 <+8>: sub rsp,0x20 0x0000555555555195 <+12>: mov rax,QWORD PTR fs:0x28 0x000055555555519e <+21>: mov QWORD PTR [rbp-0x8],rax 0x00005555555551a2 <+25>: xor eax,eax 0x00005555555551a4 <+27>: lea rax,[rbp-0x12] 0x00005555555551a8 <+31>: mov rdi,rax 0x00005555555551ab <+34>: mov eax,0x0 0x00005555555551b0 <+39>: call 0x555555555090 <gets@plt> 0x00005555555551b5 <+44>: lea rax,[rbp-0x12] 0x00005555555551b9 <+48>: mov rsi,rax 0x00005555555551bc <+51>: lea rax,[rip+0xe41] # 0x555555556004 0x00005555555551c3 <+58>: mov rdi,rax 0x00005555555551c6 <+61>: mov eax,0x0 0x00005555555551cb <+66>: call 0x555555555080 <printf@plt> 0x00005555555551d0 <+71>: mov eax,0x0 0x00005555555551d5 <+76>: mov rdx,QWORD PTR [rbp-0x8] 0x00005555555551d9 <+80>: sub rdx,QWORD PTR fs:0x28 0x00005555555551e2 <+89>: je 0x5555555551e9 <main+96> 0x00005555555551e4 <+91>: call 0x555555555070 <__stack_chk_fail@plt> 0x00005555555551e9 <+96>: leave 0x00005555555551ea <+97>: ret# PIE 끈 후 실행 전 0x0000000000401176 <+0>: endbr64 0x000000000040117a <+4>: push %rbp 0x000000000040117b <+5>: mov %rsp,%rbp 0x000000000040117e <+8>: sub $0x20,%rsp 0x0000000000401182 <+12>: mov %fs:0x28,%rax 0x000000000040118b <+21>: mov %rax,-0x8(%rbp) 0x000000000040118f <+25>: xor %eax,%eax 0x0000000000401191 <+27>: lea -0x12(%rbp),%rax 0x0000000000401195 <+31>: mov %rax,%rdi 0x0000000000401198 <+34>: mov $0x0,%eax 0x000000000040119d <+39>: call 0x401080 <gets@plt> 0x00000000004011a2 <+44>: lea -0x12(%rbp),%rax 0x00000000004011a6 <+48>: mov %rax,%rsi 0x00000000004011a9 <+51>: mov $0x402004,%edi 0x00000000004011ae <+56>: mov $0x0,%eax 0x00000000004011b3 <+61>: call 0x401070 <printf@plt> 0x00000000004011b8 <+66>: mov $0x0,%eax 0x00000000004011bd <+71>: mov -0x8(%rbp),%rdx 0x00000000004011c1 <+75>: sub %fs:0x28,%rdx 0x00000000004011ca <+84>: je 0x4011d1 <main+91> 0x00000000004011cc <+86>: call 0x401060 <__stack_chk_fail@plt> 0x00000000004011d1 <+91>: leave 0x00000000004011d2 <+92>: ret# PIE 끈 후 실행 후 # 메모리 주소가 똑같은 것을 알 수 있습니다. 0x0000000000401176 <+0>: endbr64 0x000000000040117a <+4>: push %rbp 0x000000000040117b <+5>: mov %rsp,%rbp 0x000000000040117e <+8>: sub $0x20,%rsp 0x0000000000401182 <+12>: mov %fs:0x28,%rax 0x000000000040118b <+21>: mov %rax,-0x8(%rbp) 0x000000000040118f <+25>: xor %eax,%eax 0x0000000000401191 <+27>: lea -0x12(%rbp),%rax 0x0000000000401195 <+31>: mov %rax,%rdi 0x0000000000401198 <+34>: mov $0x0,%eax 0x000000000040119d <+39>: call 0x401080 <gets@plt> 0x00000000004011a2 <+44>: lea -0x12(%rbp),%rax 0x00000000004011a6 <+48>: mov %rax,%rsi 0x00000000004011a9 <+51>: mov $0x402004,%edi 0x00000000004011ae <+56>: mov $0x0,%eax 0x00000000004011b3 <+61>: call 0x401070 <printf@plt> 0x00000000004011b8 <+66>: mov $0x0,%eax 0x00000000004011bd <+71>: mov -0x8(%rbp),%rdx 0x00000000004011c1 <+75>: sub %fs:0x28,%rdx 0x00000000004011ca <+84>: je 0x4011d1 <main+91> 0x00000000004011cc <+86>: call 0x401060 <__stack_chk_fail@plt> 0x00000000004011d1 <+91>: leave 0x00000000004011d2 <+92>: ret
4-4. ASLR
- 라이브러리에 대한 정적 주소 공격 방지 기법으로 PIE와 원리가 같습니다.
- 메모리 구조에서 Data와 heap 사이 라이브러리 영역에서 프로세스가 실행될 때마다 라이브버리의 시작 위치를 다르게 매핑합니다.
- 과거, Code reuse attack의 일종인 Ret2Libc 공격을 방어하는데 효과적이었지만, 현재는 파훼법이 등장했습니다…
- Code reuse attack은 injection 공격과 달리 코드를 공격자가 직접 작성하는 것이 아니라 원래 작성되어 있는 코드를 이용하는 공격입니다.
- Ret2Libc는 라이브러리에 작성되어 있는 코드 중 취약점이 있는 코드(ex.system)의 시작 주소를 RET에 덮어 씌워 해당 코드를 실행하는 공격입니다.
- 파훼법
libc_base = 함수_실제주소 - (함수_offset)
취약점_함수_실제 = libc_base + 취약점_함수_offset- 특정 함수의 실제 주소를 알게 된다면, offset을 실제주소에서 빼 라이브러리의 실제 시작 주소를 알아낼 수 있습니다.
- 이후, 라이브러리의 실제 시작 주소에 취약점 함수의 offset을 더하면 취약점 함수의 실제 시작 주소를 구할 수 있습니다.